Home » Microsoft » DP-100 v.2 » HOTSPOT
HOTSPOT
You are evaluating a Python NumPy array that contains six data points defined as follows:
data = [10, 20, 30, 40, 50, 60] You must generate the following output by using the k-fold algorithm implantation in the Python Scikit-learn machine learning library:
train: [10 40 50 60], test: [20 30] train: [20 30 40 60], test: [10 50] train: [10 20 30 50], test: [40 60] You need to implement a cross-validation to generate the output.
How should you complete the code segment? To answer, select the appropriate code segment in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
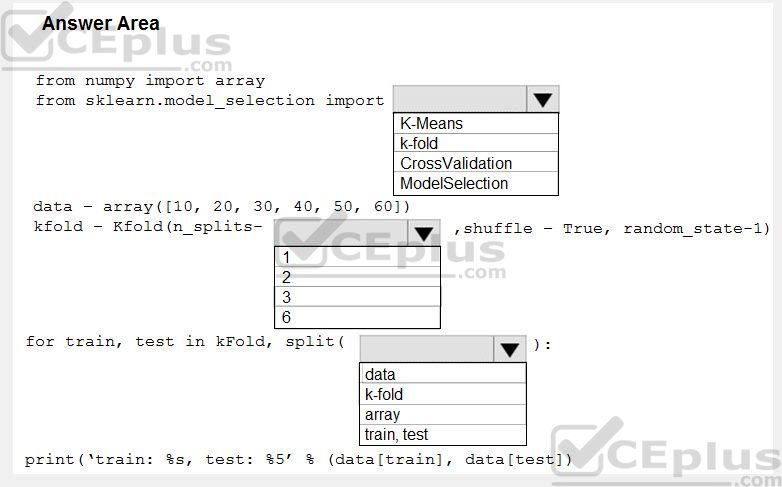
Correct Answer:
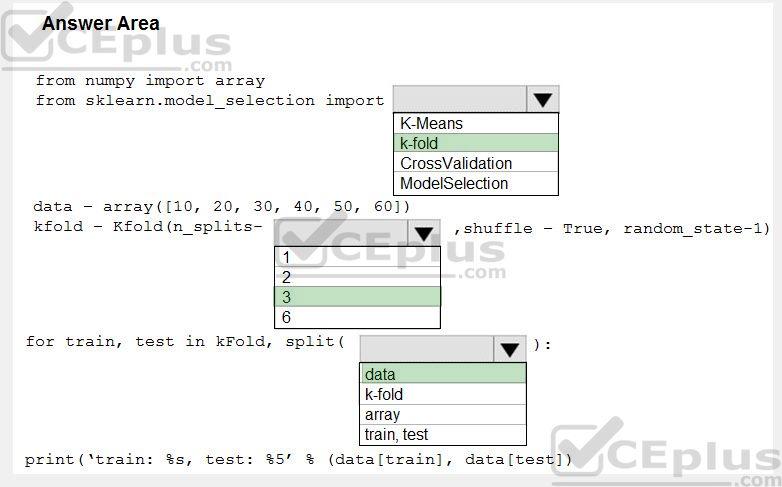
Explanation/Reference:
Explanation:
Box 1: k-fold Box 2: 3 K-Folds cross-validator provides train/test indices to split data in train/test sets. Split dataset into k consecutive folds (without shuffling by default).
The parameter n_splits ( int, default=3) is the number of folds. Must be at least 2.
Box 3: data Example: Example:
>>> >>> from sklearn.model_selection import KFold >>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) >>> y = np.array([1, 2, 3, 4]) >>> kf = KFold(n_splits=2) >>> kf.get_n_splits(X)
2 >>> print(kf) KFold(n_splits=2, random_state=None, shuffle=False) >>> for train_index, test_index in kf.split(X):
… print("TRAIN:", train_index, "TEST:", test_index) … X_train, X_test = X[train_index], X[test_index] … y_train, y_test = y[train_index], y[test_index] TRAIN: [2 3] TEST: [0 1] TRAIN: [0 1] TEST: [2 3] References:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html
