Home » Oracle » 1z0-117 » Which two statements are true about the bloom filter in the execution plan?
Examine the Exhibit.

Which two statements are true about the bloom filter in the execution plan?
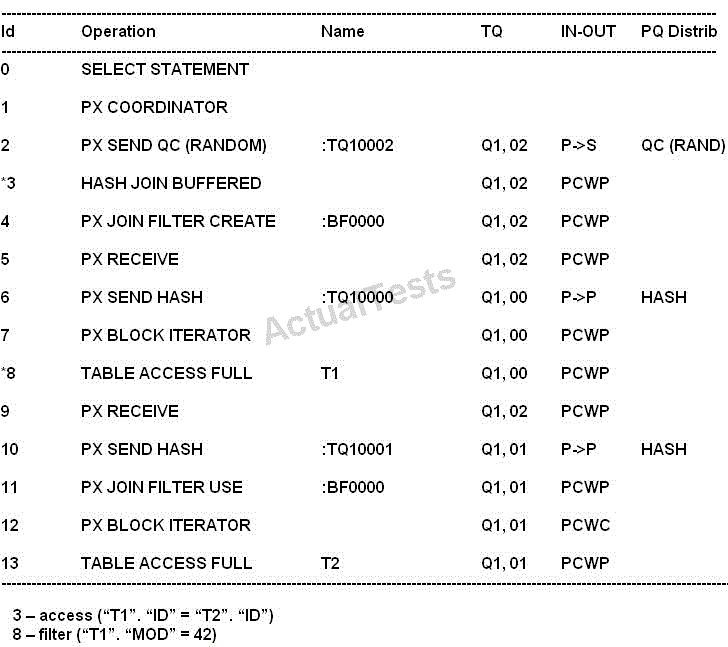
Exhibit:
A. The bloom filter prevents all rows from table T1 that do not join T2 from being needlessly distributed.
B. The bloom filter prevents all rows from table T2 that do not join table T1 from being needlessly distributed.
C. The bloom filter prevents some rows from table T2 that do not join table T1 from being needlessly distributed.
D. The bloom filter is created in parallel by the set of parallel execution processes that scanned table T2.
E. The bloom filter is created in parallel by the set of parallel execution processes that later perform join.
F. The bloom filter is created in parallel by the set of parallel execution processes that scanned table T1.
Correct Answer: BF
Explanation/Reference:
* PX JOIN FILTER CREATE
The bloom filter is created in line 4.
* PX JOIN FILTER USE
The bloom filter is used in line 11.
Note:
*You can identify a bloom pruning in a plan when you see :BF0000 in the Pstart and Pstop columns of the execution plan and PART JOIN FILTERCREATE in the operations column.
*A Bloom filter is a probabilistic algorithm for doing existence tests in less memory than a full list of keys would require. In other words, a Bloom filter is a method for representing a set of n elements (also called keys) to support membership queries.
*The Oracle database makes use of Bloom filters in the following 4 situations:
- To reduce data communication between slave processes in parallel joins: mostly in RAC
- To implement join-filter pruning: in partition pruning, the optimizer analyzes FROM and WHERE clauses in SQL statements to eliminate unneeded partitions when building the partition access list
- To support result caches: when you run a query, Oracle will first see if the results of that query have already been computed and cached by some session or user, and if so, it will retrieve the answer from the server result cache instead of gathering all of the database blocks
- To filter members in different cells in Exadata: Exadata performs joins between large tables and small lookup tables, a very common scenario for data warehouses with star schemas. This is implemented using Bloom filters as to determine whether a row is a member of the desired result set.
|
Download Printable PDF. VALID exam to help you PASS.
|
 |